1.0.83
July 1, 2025
Version 1.0.83Improved Root Cause Views
We've redesigned our Root Cause views to help you quickly identify and address the most urgent service-impacting issues. The new interface prioritizes critical root causes based on their impact scope and severity, making incident triage more efficient than ever.
API Documentation Now Available
Our comprehensive GraphQL API documentation is now available! Programmatically access Causely's root cause analysis engine, query defects, and integrate with your CI/CD pipelines.
Smarter Post-Deployment Analysis
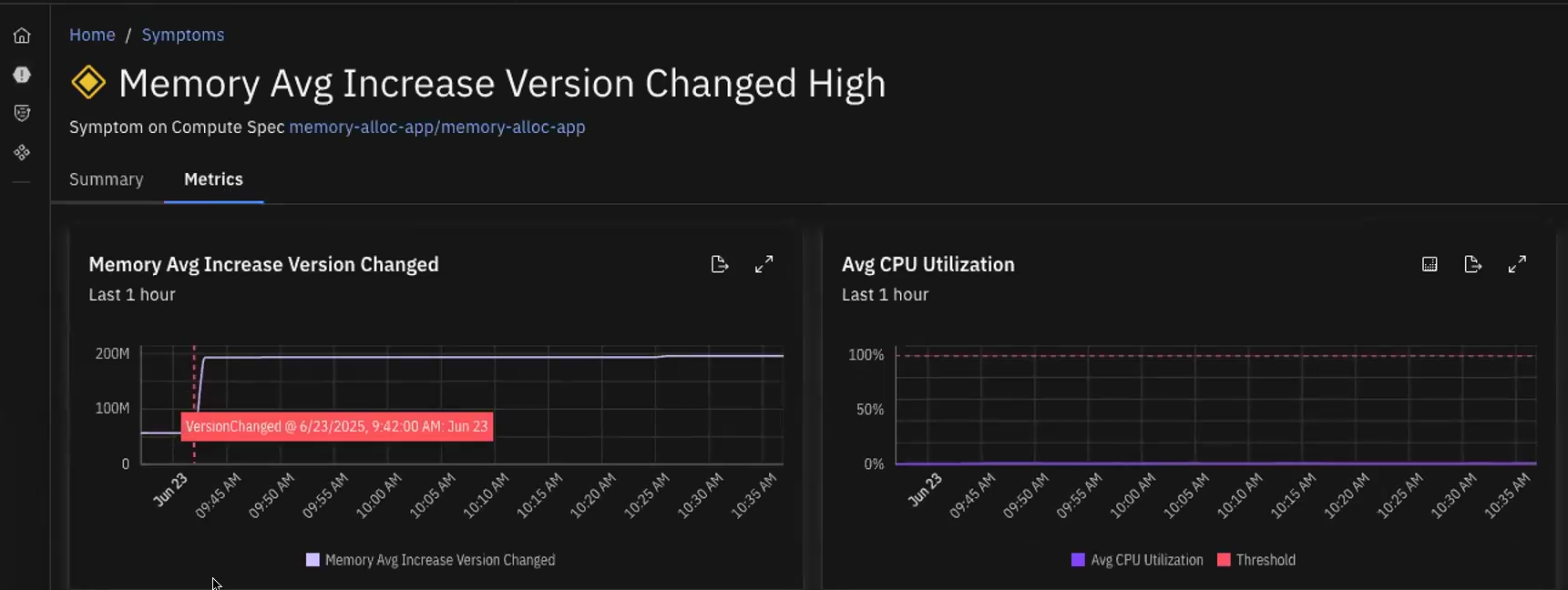
Causely now provides enhanced visibility into code change-related root causes with improved clarity around version change events:
- Immediate Detection: Catch resource usage changes right after a deployment to identify regressions faster
- Precise Correlation: Version timestamps are now directly correlated with resource metrics like CPU, memory, and latency
- Before vs. After Insights: Get proactive visibility into what changed pre and post-deployment
- Automatic Code Change Attribution: Causely automatically infers if a root cause stems from a code change, helping teams quickly connect symptoms to recent deployments
This feature is particularly valuable for understanding the real performance impact of new releases on your services.
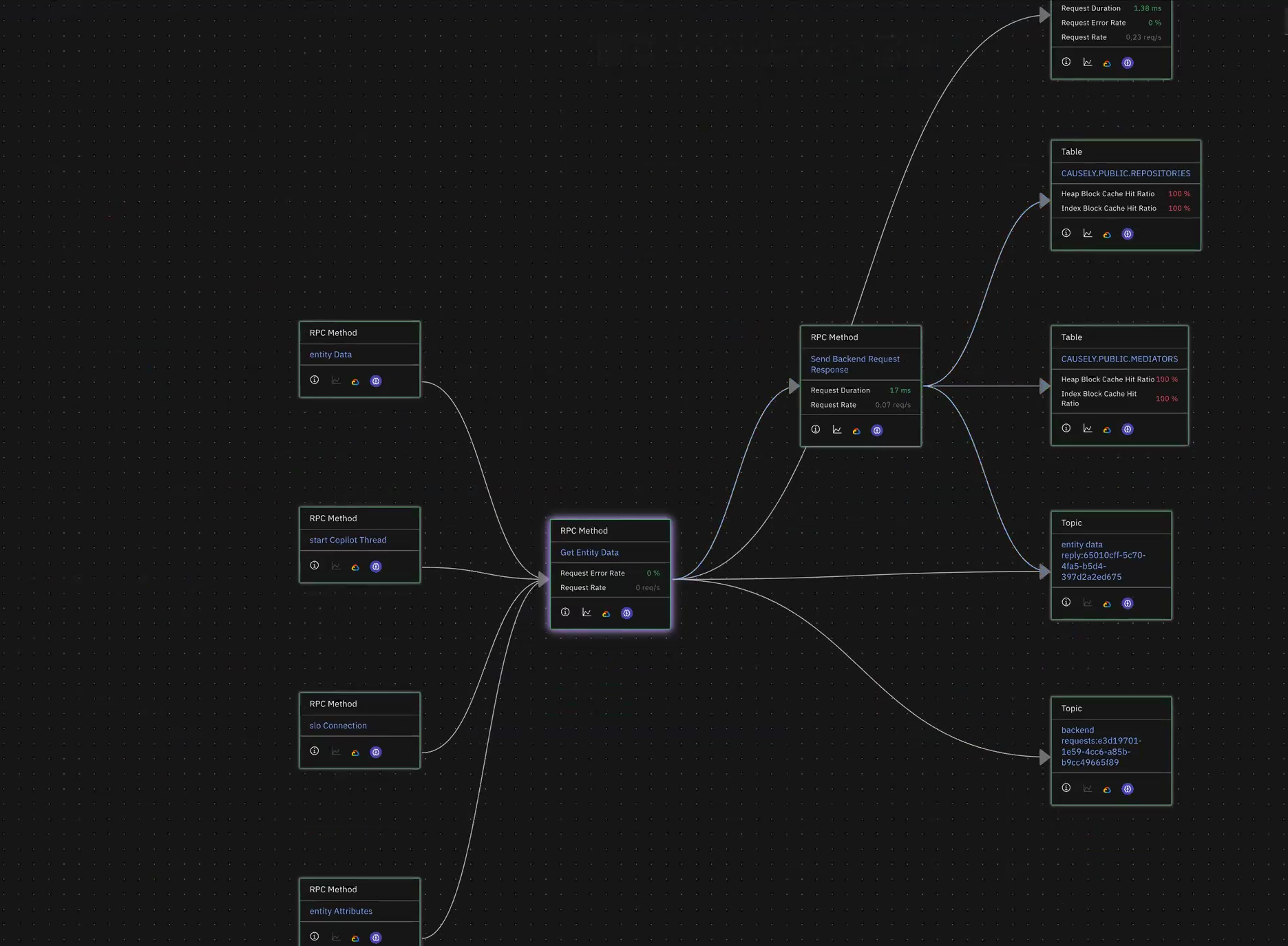
Better Visibility Into Asynchronous Data Flows
Understanding complex message flows across your distributed system just got easier with our improved data flow graphs:
- End-to-End Tracing: Follow messages from publish to RPC method or HTTP path, even across multiple service hops
- Topic Filtering: Isolate behavior for specific customers or queues by filtering data flows by topic
- Causal Integration: These improvements are fully integrated into our causal engine, enhancing root cause accuracy for asynchronous systems
Did you know?
Scopes in Causely allow you to define and manage custom subsets of your environment's topology. As Causely automatically discovers the full topology of your environment, it can present a rich but potentially overwhelming set of entities—services, infrastructure components, and identified problems. Scopes help you focus on the specific subset of data that matters most to your role, responsibilities, or current investigative tasks.
Learn more about scopes and how to use them in our documentation.
Bug Fixes and Minor Improvements
- Database Performance: Added indices to active actions and increased max DB pool connections for better performance
- Slack Integration: Enhanced support for users in multiple Slack teams
- Kubernetes Improvements: Added option to disable entity log collection from Kubernetes and improved pod metadata for network endpoints
- Alert Management: Added alerts as context in symptoms and implemented continuous sender for alert manager notifications
- Log Management: Optimized log storage by limiting to 1000 log lines per evidence
- UI Improvements: Fixed time duration format display and headline database scanning
- Root Cause Quality: Filtered out root causes with only low probability symptoms and fixed flapping issues due to equal probabilities
- Monitoring Enhancements: Added support for symptom monitoring from Prometheus and improved topology scraper metrics for SLOs
- SQL Parsing: Enhanced SQL query parsing for better database performance analysis
- Email Notifications: Improved weekly email summary delivery system