v1.0.105
December 9, 2025
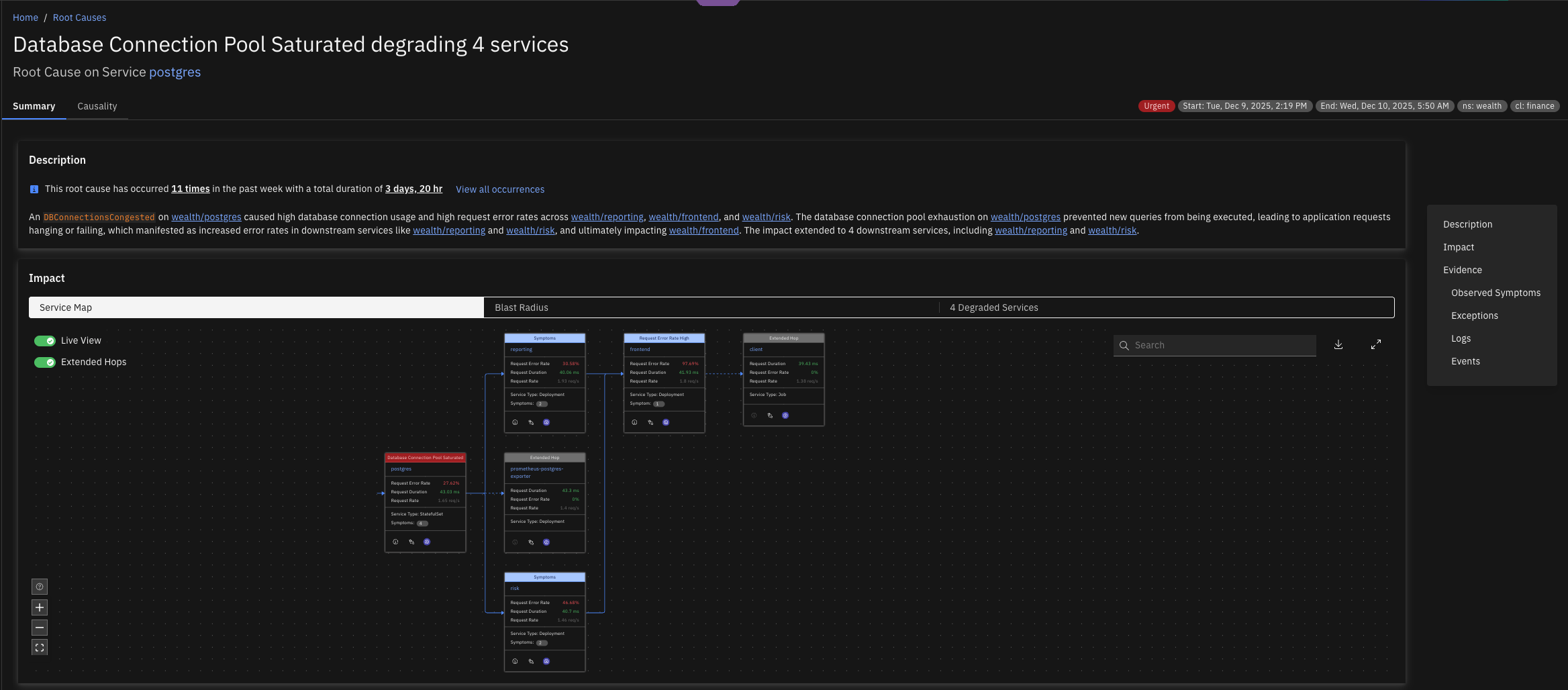
Version v1.0.105Impacted Services Graph
Causely now provides a dedicated Impacted Services Graph that makes it easier to understand how a reliability issue propagates across your environment.
This new view enables you to:
- Visualize the full impact of a root cause, including all degraded downstream services
- See live service-level metrics in context, directly within the graph
- Toggle extended hops to understand which additional services may be at risk if the issue remains unresolved
- Navigate seamlessly to the Live Topology view for any degraded service to continue investigation in real time
This makes it significantly easier for teams to assess the scope, urgency, and potential blast radius of reliability issues.
Datadog Dual Shipping & Hybrid Environment Support
Causely now supports Datadog APM dual shipping, allowing teams to reuse existing Datadog instrumentation while sending trace data from the Datadog collector directly to the Causely mediator without incurring additional egress costs.
This release also extends Datadog support to services running outside Kubernetes (such as standalone EC2 instances). As a result, Causely can now construct a complete, accurate causal model across heterogeneous environments, a prerequisite for:
- Confidently validating reliability in pre-production (load tests, release candidates)
- Continuously assuring reliability in production
- Detecting drift or regressions caused by infrastructure or configuration changes
Datadog monitors can also be ingested as symptom identifiers, enriching Causely's understanding of the environment.
Expanded Dynatrace Support for Mixed Container Platforms
Causely's Dynatrace integration has been expanded beyond Kubernetes to include ECS-based services. This ensures that teams using Dynatrace across multiple container platforms get a unified dependency and service map that reflects how the system actually behaves under change.
Enhancements include:
- Cross-platform stitching between ECS and Kubernetes workloads
- Service-level metric ingestion for more reliable behavior modeling
- Improved tracing fidelity for clearer dependency pathways
Together, these improvements help Causely maintain an end-to-end causal understanding of services regardless of where they run, strengthening reliability assurance across hybrid environments.
Did you know?
Causely allows you to automatically remediate resource contention issues directly from the UI, helping you restore performance faster, reduce time to resolve, and keep services within SLOs. When Causely identifies a deterministic Resource Contention root cause, you can trigger automated remediation or apply a guided fix with one click. Learn more.
Minor Improvements
- Added the ability to filter on external services
- Added support for multitenant Loki
- Improved Ask Causely search by enabling lookup by entity name
- Reduced duplication of services across Docker, Nomad, and Kubernetes environments
- Updated default SLO burn rate threshold from 2 to 4, making urgent root causes more reflective of sustained reliability degradation rather than short-lived spikes
- Improved snapshot reliability by fixing an issue that sometimes caused snapshot generation to time out in the UI
- Reduced Beyla log verbosity so logs remain clean and actionable without excessive noise
- Added notifications for missing agent coverage on nodes, making it easier to detect when parts of the infrastructure are not reporting the telemetry required for complete reliability analysis