v1.0.110
January 26, 2026
Version v1.0.110Ask Causely: Natural Language on Logs and Alerts
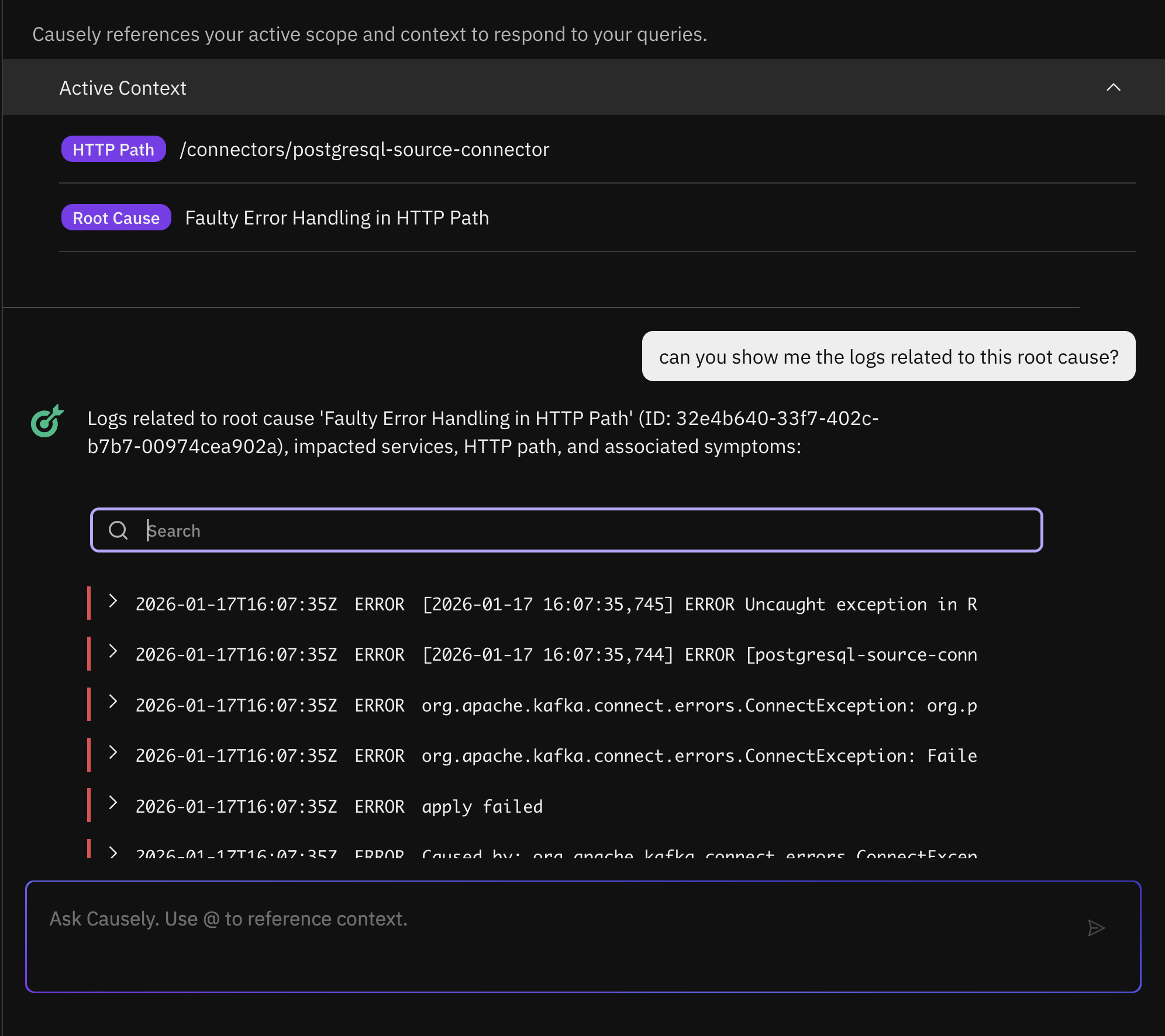
Ask Causely can now answer follow-up questions about logs associated with a specific root cause. Causely already infers the true root cause using its causal model and automatically correlates relevant errors and warnings from the affected services or containers. With this update, you can dig deeper by asking targeted questions to filter and retrieve specific logs, such as:
- "Can you show me all the error level logs associated with this root cause?"
- "Can you show me the logs related to Kafka on this root cause?"
Ask Causely also better understands alerts. If you paste an alert from Prometheus or Datadog, it can identify the underlying root cause or determine that the alert is spurious, with clear evidence so you don't waste time investigating noise.
Minimum Threshold for Learned Latency
You can now configure a minimum value for Causely's learned latency (request duration) thresholds. By default, thresholds are learned from the p95 request duration over the last 24 hours, which can become too sensitive in low-traffic scenarios. The minimum threshold prevents unnecessary noise, for example when traffic dips over the weekend and spikes on Monday.
This can be configured for services via the UI, and for HTTP paths or RPC methods via the API.
Prioritizing Dataflows with SLOs (API-only)
You can now assign SLOs to specific HTTP paths or RPC methods to prioritize critical user flows. This is currently configurable through the API. When an SLO is at risk or violated, any root causes affecting that endpoint or its upstream dependencies are automatically treated as urgent. This helps teams focus on issues that directly impact key business journeys, such as checkout.
Minor Improvements
- Improved Kubernetes API caching to support clusters with thousands of nodes while reducing API load
- Added support for connecting to remote Kubernetes clusters for service discovery without deploying a mediator in every cluster
- Improved OpenTelemetry trace support in standalone Docker environments so traces connect correctly to relevant entities
- Removed scope constraints when defining notification filters for more flexible alert routing