Latest Releases
Each release of Causely includes new features, bug fixes, and performance improvements. This page provides highlights of the most recent releases.
Have ideas, questions, or feedback? Please reach out to us at community@causely.ai.
Overview
Each release of Causely includes new features, bug fixes, and performance improvements. This page provides highlights of the most recent releases.
To get details on older releases, please go to the changelog page, listing all releases.
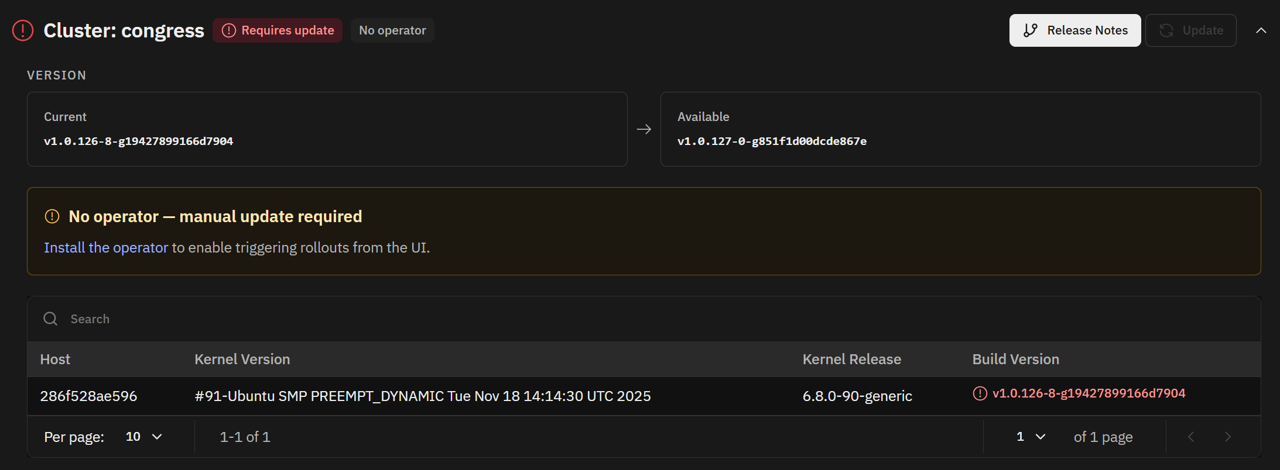
Redesigned Mediators Page
The Mediators page has been redesigned with two additions that give teams more visibility and control over their mediator deployments.
Release notes link: When a new mediator version is available, a Release Notes link now appears directly on the page. Previously, the version update notification provided no context about what changed, requiring users to look up release notes separately. The link surfaces that context in place, so teams can assess whether an update is urgent without leaving the product.
Operator status: The page now surfaces whether the Causely Operator is installed for each cluster. When no operator is detected, a notice indicates that manual update is required and links to operator installation instructions. When the operator is installed, version updates can be triggered directly from the UI without a manual Helm upgrade. Learn more about the Causely Operator
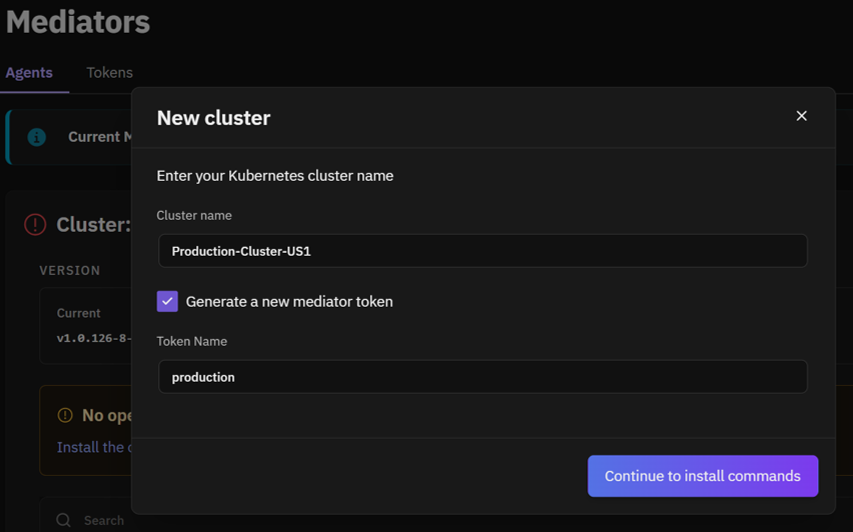
Streamlined Mediator Setup
Adding a new mediator now walks you through cluster naming and token generation in a single, consolidated flow. The installation command is available to copy directly from the setup screen, removing the need to navigate between steps to gather the information needed to complete an installation. The mediator token is displayed once during setup, at the point where it is needed.
Minor Improvements
- RabbitMQ MassTransit traces: Causely now parses RabbitMQ MassTransit trace data, extending trace coverage for environments that use MassTransit as a messaging framework over RabbitMQ.
- Topology search: Fixed a bug where the filter search bar disappeared after returning results in the topology view. The search bar now persists after a search, and results can be cleared to return to the default state.
- Log volume limits for root causes: Log collection per root cause is now capped at 500 lines per service and 2,000 lines per defect. This prevents evidence sets from growing to 10,000+ lines and keeps root cause data focused and fast to load.
- Docker service instance cleanup: For Docker installations, stale service instance ID labels left behind after a process ID change are now removed automatically. This prevents topology noise from accumulating in Docker-based environments.
Generic Application Error Log Detection
Causely now detects generic application errors in logs and incorporates them into the causal model via a new Application Error Spike symptom and root cause. Previously, log-based root cause detection relied on predefined error patterns; errors that did not match a known pattern were not surfaced. When Causely observes more than 2,000 generic errors within a one-hour window, it activates the application error log symptom, which is then used in continuous root cause analysis to help agents and on-call engineers identify and resolve the underlying issue faster. Note that the threshold for error log symptom activation is configurable, see more detail in threshold configuration.
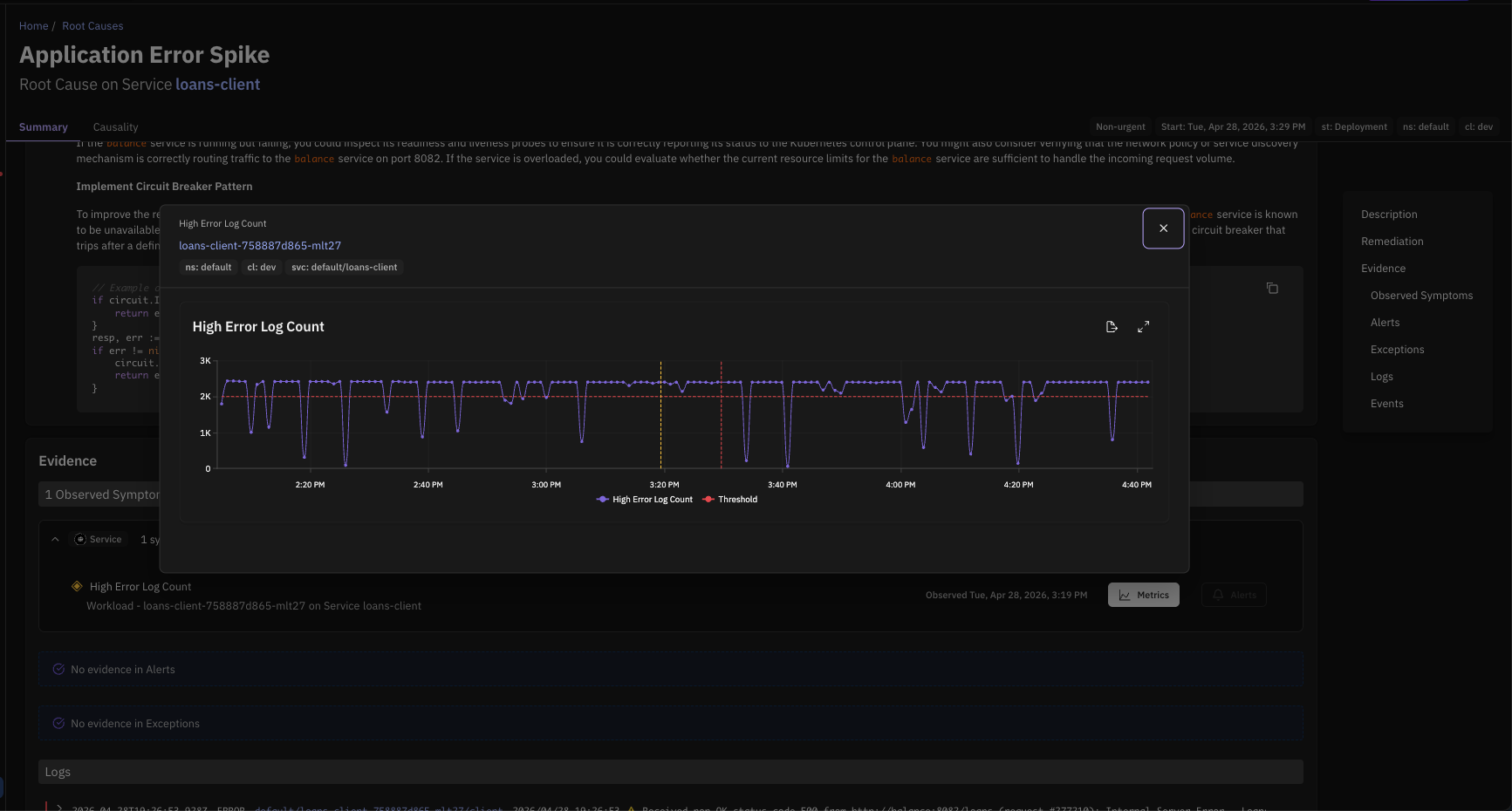
Learn more about log-based root causes
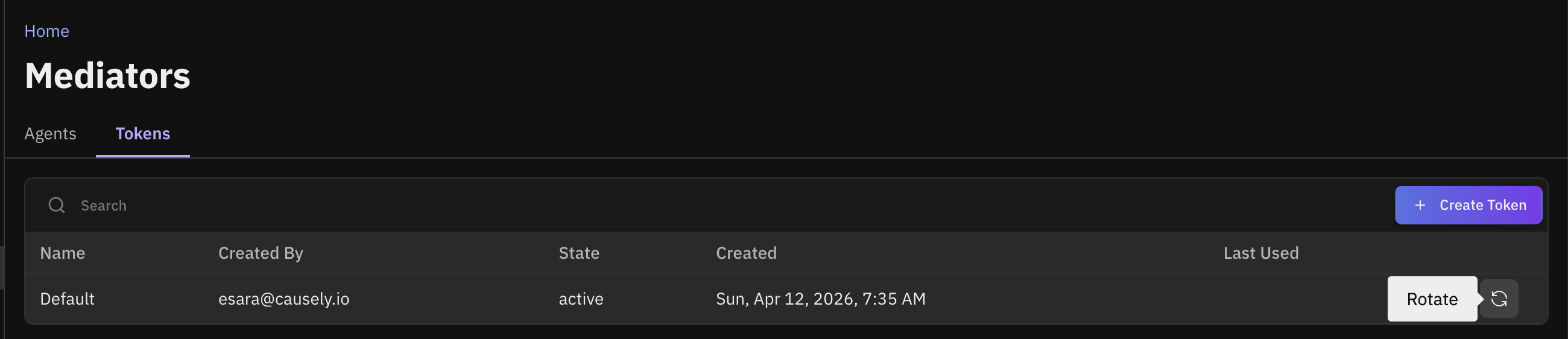
Token Management and Developer Role
Causely now supports rotating and revoking the tokens used with the Causely mediator, and introduces a new Developer role. Developers can add new mediators and manage tokens for those mediators; Administrator roles retain the ability to manage tokens across all mediators in a tenant. Read Only users cannot add mediators or manage tokens.
Minor Improvements
- AWS RDS database cluster support: Causely now identifies both the overall RDS cluster and its individual databases, improving visibility into database-layer root causes.
- Symptom activation timing: Improved the symptom activation delay logic to better distinguish bursty anomalies from sustained ones. Learn more
- Generic webhook notifications: Improved support for sending Causely notifications to generic webhooks. Learn more
- Agent-not-deployed false positives: Addressed incorrect "Causely agent is down" symptom activation for nodes where an agent was intentionally not deployed.
- Elasticsearch integration: Addressed an issue affecting the Elasticsearch integration.
- Service logs tab: Clarified that errors and warnings shown in the Service logs tab reflect the last 5 minutes of activity.
- Node malfunction detection: Improved detection of the node malfunction root cause to correctly handle scenarios where nodes are automatically removed by autoscaling mechanisms.
Expanded MCP Coverage
The Causely MCP server adds five new tools and six new prompts, giving AI agents and automation workflows a broader set of operational capabilities without requiring custom context engineering.
New tools cover structured health summaries for any entity or full environment (get_entity_health, get_environment_health), integration status visibility (get_integration_status), label enumeration for filtering and search (get_label_values), and structured incident ticket generation (generate_ticket). Agents can now answer a wider range of operational questions, from environment-wide health snapshots to integration coverage gaps, using structured, causal-grounded outputs rather than raw telemetry.
New prompts cover error rate ranking across services, resource usage leadership, data asset consumer mapping, historical incident windows, external alert mapping to Causely's causal model, and database-focused investigation workflows. These give agents and users pre-built starting points for the most common observability and reliability queries.
Expanded Root Cause Coverage
Causely now detects and models additional root causes across Postgres, Redis, MongoDB, Kafka, and Kubernetes Node infrastructure, reducing the gap between where symptoms surface and where the actual cause lives.
Without these models, agents and on-call engineers must manually correlate infrastructure signals to application degradation. With them, Causely can identify the true origin of an incident, connection pool exhaustion, replication lag, storage pressure, and suppress downstream symptoms that would otherwise generate noise.
-
Postgres: Cache hit rate degradation, checkpoint I/O pressure, connection slot exhaustion, deadlock storms, idle-in-transaction accumulation, lock contention, replication lag, and query memory spill to disk.
-
Redis: Cache miss storms, command queue saturation, memory pressure, and connection exhaustion.
-
MongoDB: Connection exhaustion, cursor pressure, and replica lag.
-
Kafka: Partition outages, replication degradation, and storage pressure.
-
Kubernetes Node: Causely Agent down detection, with root cause attribution across container runtime, filesystem, kernel, Kubelet, network, PID pressure, and malfunction conditions.
Example troubleshooting queries using Claude and Causely MCP


Log-Based Application Root Cause Detection
Causely now monitors application logs continuously and activates symptoms based on defined error patterns, extending causal analysis to common application-level failure modes.
Causely already captures and surfaces container logs alongside detected symptoms and root causes. These new root causes go further, continuously monitoring those logs for defined error patterns and feeding matching signals directly into Causely's causal analysis, so application-level failures are identified as named root causes rather than requiring manual log inspection to interpret.
This new capability adds 25 new application root causes spanning Java, Python, Go, and .NET runtimes, web and proxy layers (Nginx, HAProxy), and data systems (Cassandra, Elasticsearch, MySQL, RabbitMQ).
Minor Improvements
- MCP authentication: Static OAuth credential support added so long-running background agents no longer need to re-authenticate via bearer token. Learn more
- AWS ECS log retrieval: Agents and workflows can now retrieve logs from ECS containers.
- Operator update control: Automated update behavior is now configurable per cluster. Learn more
- Dynatrace management zones: Causely now discovers Dynatrace management zones and applies corresponding labels for search and filtering.
- Dynatrace alert polling: Increased monitoring frequency for faster detection of Dynatrace alert state changes.
- Notification payload: Expanded payload content for Causely alert notifications.
- Scope and topology filtering: Improved accuracy and coverage of scope and topology filters.
- Beyla 3.7.0: Updated to Beyla 3.7.0, improving trace fidelity for encrypted Java and Kafka communications.
More Releases
Go to the changelog page.