v1.0.131
Pyrra SLO Support
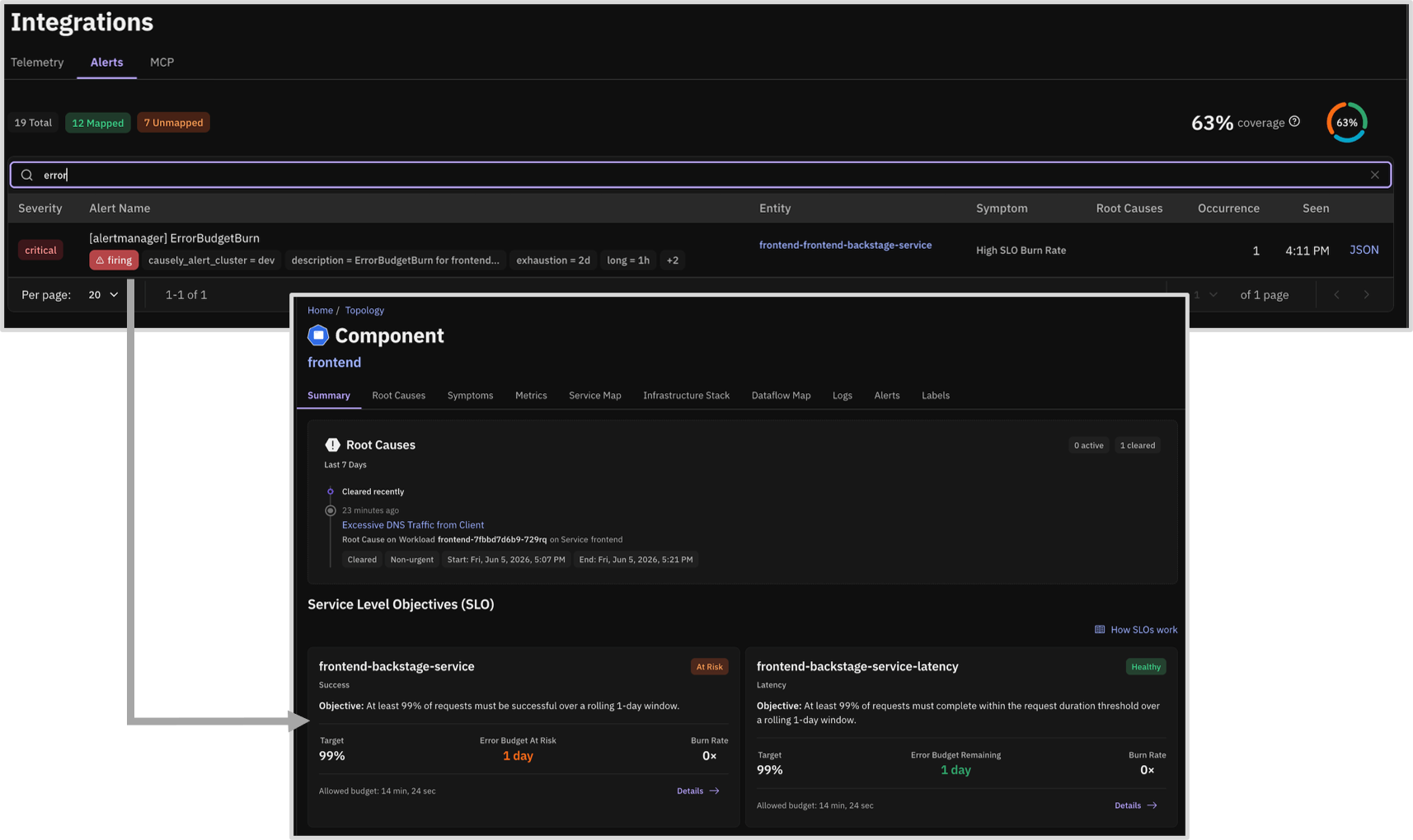
Causely now brings externally defined SLOs from Pyrra into the product as first-class signals. Previously, teams that defined service and business objectives in Pyrra had to monitor SLO health in one place and investigate root causes in another, with no connection between the two. Causely now discovers Pyrra ServiceLevelObjective definitions automatically — from both the Pyrra CRD and PrometheusRule-based deployments — and binds each SLO to the correct service in the Causely topology.
Once discovered, SLO health, including error budget and burn rate, is visible on the associated service in both the UI and the MCP server. SLOs can also be surfaced on Business Applications: when a Pyrra SLO carries a Backstage component label, Causely attaches it to the corresponding Business Application discovered from Backstage, lifting SLO risk from the service level to the business level. Because SLOs are tied into the causal model, root cause analysis can now explain why an SLO is at risk or violated, tracing business impact down to the contributing service and infrastructure causes.
MCP Server Updates
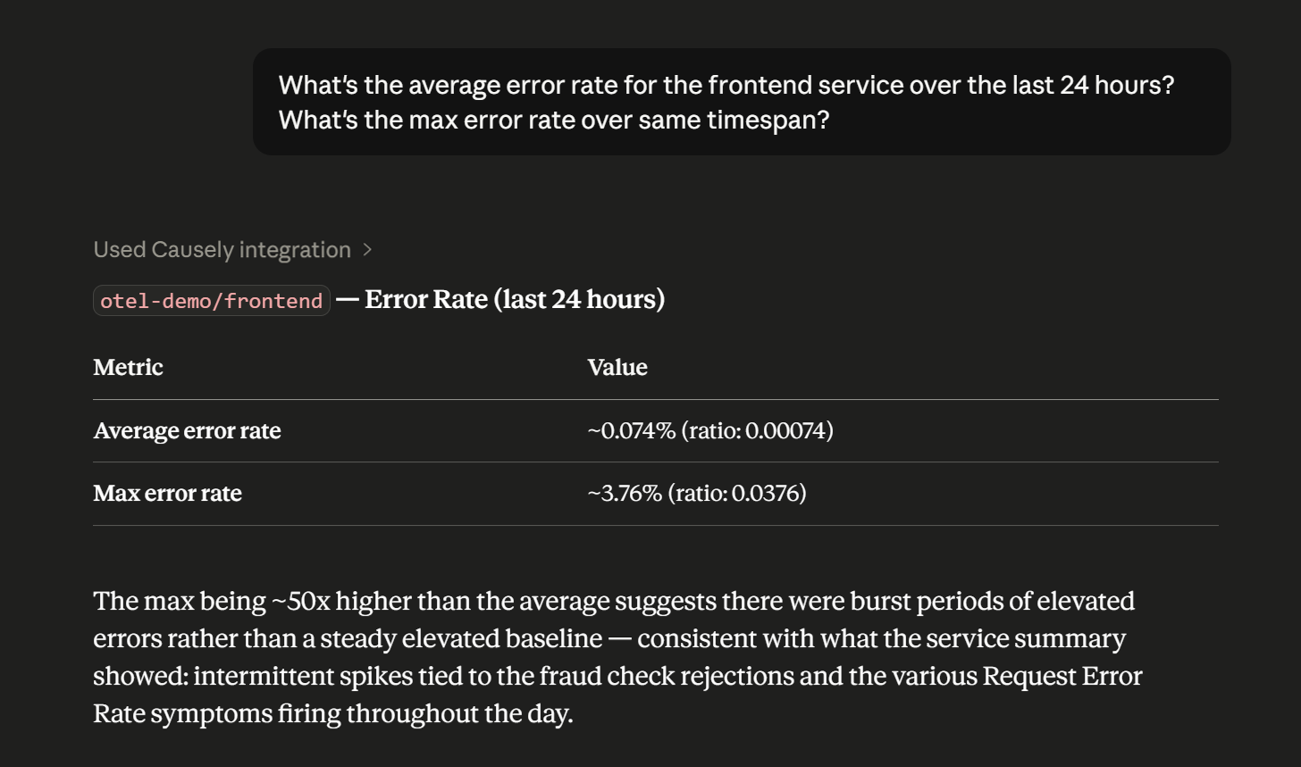
The get_metrics tool now accepts an aggregate parameter supporting 10 operations: mean, sum, min, max, latest, first, p95, count, delta, and pct_change. When set, the tool reduces a full time-series down to a single scalar value, eliminating the need for client-side computation. Agents can request an aggregate directly instead of retrieving raw series and computing summaries themselves, which reduces output size, token usage, and the number of steps needed to answer questions about metric behavior. The tool also now covers metrics for Gen AI and agentic workloads.
Minor Improvements
- Kubernetes discovery performance: Improved initial discovery time for the Kubernetes controller in large clusters, reducing initial full sync from many minutes to a fraction of the time. Agents also now tolerate slow informer startup, waiting up to 30 minutes for node information before failing, which prevents spurious agent restarts during discovery in large environments.
- Entity cleanup: Fixed a bug where stale entities were not garbage-collected in the mediator. Entities that are no longer observed are now cleaned up correctly.